
如果这篇博客帮助到你,可以请我喝一杯咖啡~
CC BY 4.0 (除特别声明或转载文章外)
一 C++ 是 C 的超集
二 面向对象 和 面向过程
三 继承,封装,多态
1. 封装
2. 继承
不同方式的继承
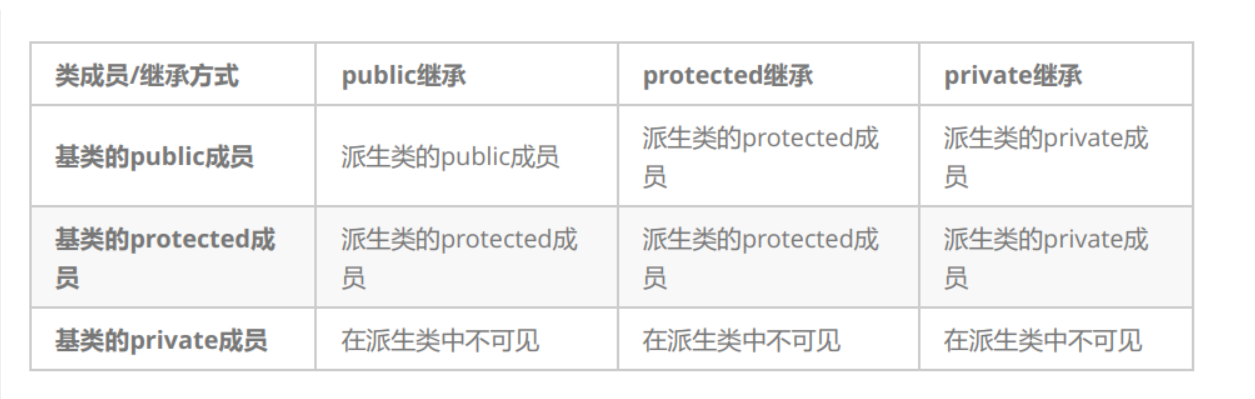
- 在实际运用中一般使用都是public继承,几乎很少使用protetced/private继承
- Min(成员在基类的访问限定符,继承方式),public > protected > private
切片
派生类对象 可以赋值给 基类的对象 / 基类的指针 / 基类的引用。这里有个形象的说法叫切片或者切 割。寓意把派生类中父类那部分切来赋值过去
父类的引用/指针 引用/指向 子类的对象,其实就是把子类切给了父类
但是子类引用/指针 引用/指向 父类的对象就会不安全,可能存在越界问题。
下面我们讨论一下这个问题:
两个类:
class Person
{
public:
void print()
{
cout << "age = " << _age << " name = " << _name << " " << _test << endl;
}
public:
int start;
protected:
int _age = 20;
string _name = "Shepard";
private:
int _test = 1;
};
class Student2 : public Person
{
public:
void setAge(int age)
{
_age = age;
}
public:
int id = 1234;
};
.
void test2()
{
Person p;
Student2 s;
// 切片操作,把子类的一部分(整体)切给父类
// 切片不是隐式类型转换,是安全的
p = s;
Person& rp = s;
Person* pp = &s;
// s = p; // 子类对象不能用父类对象来赋值
// 可以强转父类类型,但是这样不安全,可能会访问越界
// 指针的类型决定能访问的内存大小。
// 因为 Student2 类型大小大于其父类,所以 Student2* 能访问的内存更多
// 指针是 Student2 类型,ps 实际指向的是 Person 类型对象
Student2& rs = (Student2&)p;
Student2* ps = (Student2*)&p;
cout << rs.id << " " << ps->id << endl; // -858993460 -858993460
// 这样写是安全的,指针是 Student2 类型,ps 实际指向的也是 Student2 类型的对象
Student2& rs2 = (Student2&)rp;
Student2* ps2 = (Student2*)pp;
cout << rs2.id << " " << ps2->id << endl; // 1234 1234
}
由于引用底层也是用指针实现的,说白了这个问题就是 指针的类型可以决定指针 ++ --操作的步长。放在类中来说,子类可能具有更多的成员,占用更多的内存,而父类不存在这些成员
void test2p()
{
Person p;
Student2 s;
Student2* ps = (Student2*)&p;
s.setAge(26);
ps->print();
}
// 输出:
age = 20 name = Shepard 1
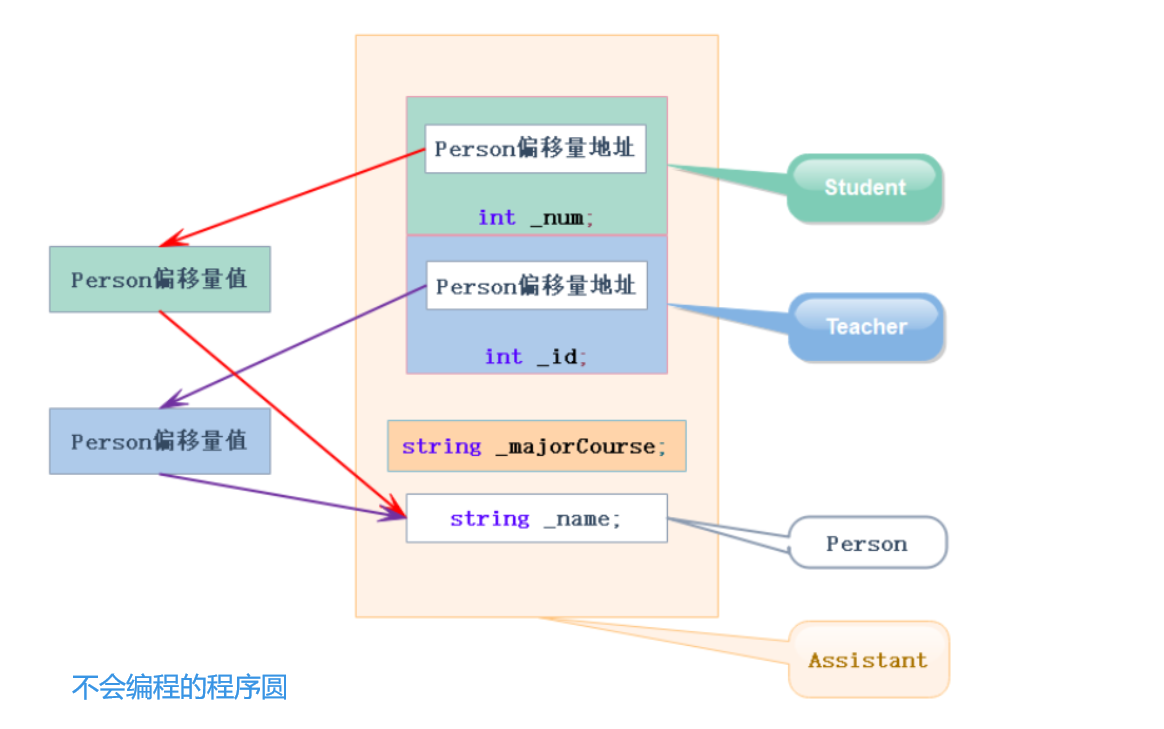
为什么 ps->print() 调用父类的 print() 成员函数?
因为 ps 是指向父类对象的指针。
而 ps->id 会输出无意义的值,这是因为 父类没有 id 这一字段。
为什么 ps 可以访问到 id?
因为 ps 是 Student2 类型的指针
那 ps->id 究竟访问的是哪里?
void test2p()
{
Person p;
Student2 s;
Student2* pp = (Student2*)&p;
// pp 是指向 Person 类型的指针
// start 是 Person 类中的第一个成员变量,所以它的地址就是Person 类型对象 p 的首地址
// 用 Person 对象的首地址减去 pp->id 的地址,我们就可以知道 pp->id 相对于 p 首地址的偏移量
cout << &pp->start - &pp->id << endl;
Student2* ps = &s;
// ps 就是指向 Student 类型的指针
// 计算结果可以看出 成员 id 相对于 Student 类型对象 s 首地址的偏移量
cout << &ps->start - &ps->id << endl;
// 输出都是 10
// 这说明,对对象的成员访问实际上是靠指针偏移量完成的
}
ps-id 访问的就是对象 p 的首地址向后偏移 10 个字节处开始的 4 个字节(一个 int 的大小)
同名隐藏
子类和父类中有同名成员,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫隐藏,也叫重定义。(在子类成员函数中,可以使用
基类::基类成员显示访问)
如何理解 隐藏 的含义呢?
有两个类:
class Person
{
public:
void print()
{
cout << _age << " " << _name << " " << _test << endl;
}
protected:
int _age = 20;
string _name = "Shepard";
private:
int _test = 1;
};
class Student3 : public Person
{
public:
void print()
{
}
protected:
int _age = 26;
};
子类的 print 函数暂时没写,下面我们一步一步来写。
注意到父类和子类都有成员变量 _age,成员函数 print()
先让 print 函数只打印 _age 成员变量
void print()
{
cout << _age << endl;
}
Student3 s;
s.print();
这里设计两个问题:
- s 对象会调用父类的
print函数还是子类的print函数? - print 函数会输出父类的
_age还是子类的_age?
这两个问题其实是一个问题,测试输出,发现 **调用的都是子类的成员 **
要想通这个问题,首先我们要了解一个概念:
父类和子类的作用域独立,可以有同名的成员
那么如何调用父类的成员呢?
cout << Person::_age << endl;
Person::print();
通过 基类::基类成员 的方式。
那有朋友可能要说:
这所谓的隐藏的含义不就是作用域的覆盖吗?
这和 C 语言的作用域覆盖有些区别,C 语言中:
int age = 20;
int main(void)
{
int age = 30;
printf("%d\n", age);
return 0;
}
得到的输出是 30,但是如何在定义了 age 后,直接使用变量名 age 访问全局变量 age 呢?C 语言可能没有办法做到这一点,但是 C++ 可以:
// 这是全局的 print
void print()
{
cout << "global" << endl;
}
class Student3 : public Person
{
public:
void print()
{
// 访问父类的 print
Person::print();
// 访问全局的 print
::print();
}
protected:
int _age = 26;
};
访问其他 作用域(块/命名空间) 中的变量/函数都需要指明作用域。
成员函数
/**
* 成员函数
*/
class Person2
{
public:
Person2(string name = "Shepard", int age = 20)
:_name(name)
,_age(age)
{
cout << "Person2(string = , int = )" << endl;
}
Person2(string name, int age, int nouse)
:_name(name)
,_age(age)
{
cout << "Person2(string, int)" << endl;
}
Person2(const Person2& p)
:_name(p._name)
,_age(p._age)
{
cout << "Person2(const Person2& p)" << endl;
}
Person2& operator=(const Person2& p)
{
if (this != &p)
{
_name = p._name;
_age = p._age;
cout << "Person2& operator=(const Person2& p)" << endl;
}
return *this;
}
~Person2()
{
cout << "~Person2()" << endl;
}
protected:
string _name;
int _age;
};
class Student4 : public Person2
{
// 如果没有显示的调用父类的构造函数,编译器自动调用父类的默认构造函数,完成父类成员的初始化
// 如果父类没有默认构造函数,必须显示的调用
public:
// 自定义的默认构造也会调用父类的默认构造(初始化列表处)
// 先构造父类,然后再构造子类
// 调用父类的默认构造
Student4(int id = 1234)
:_id(id)
{
cout << "Student4(id = )" << endl;
//cout << _name << " " << _age << " " << _id << endl;
}
// 指定调用父类的构造函数
// 先构造父类然后再初始化子类的成员
Student4(int id, int nouse)
:Person2("Samantha", 26)
,_id(id)
{
cout << "Student4(int, int)" << endl;
//cout << _name << " " << _age << " " << _id << endl;
}
// 1.编译器自动生成的拷贝构造调用父类的拷贝构造
// 2.显示定义的拷贝构造调用父类的默认构造
// 3.调用父类拷贝构造就是切片操作
Student4(const Student4& s)
:Person2(s) // 切片
// 也可以 Person(s._name, s,_age) 调用父类的默认构造
,_id(s._id)
{
cout << "Student4(const Student4& s)" << endl;
}
// 1.编译器自动生成的赋值运算符重载函数调用父类的赋值运算符重载函数
// 2.显示定义的赋值运算符重载函数不会调用父类的,因为同名/成员隐藏
// 需要显示调用父类的赋值运算符重载函数
Student4& operator=(const Student4& s)
{
if (this != &s)
{
Person2::operator=(s);
_id = s._id;
cout << "Student4& operator=(const Student4& s)" << endl;
}
return *this;
}
// 自动调用父类析构
// 先调用子类析构然后调用父类析构
~Student4()
{
cout << "~Student4()" << endl;
// ~Person2(); // 不能直接调用析构,因为底层子类和父类的函数名相同,构成函数隐藏
//Person2::~Person2(); // 不管是否显示调用父类析构,编译器都会自动调用一次父类析构
// 不要显示的调用父类析构,可能会造成资源的二次释放
}
protected:
int _id;
};
void test4()
{
//Student4 s(4321, 0);
Student4 s2;
//Student4 copy(s2);
//s = s2;
}
友元与静态成员
- 友元关系不能继承,也就是说基类友元不能访问子类私有和保护成员
- 基类定义了static静态成员,则整个继承体系里面只有一个这样的成员。无论派生出多少个子类,都只有一 个static成员实例 。
菱形继承 和 菱形虚拟继承
菱形继承
class A
{
public:
int _a = 0xa;
};
class B : public A
{
public:
int _b = 0xb;
};
class C : public A
{
public:
int _c = 0xc;
};
class D : public B, public C
{
public:
int _d = 0xd;
};
上面的这种继承关系就是典型的菱形继承,用图来表示:
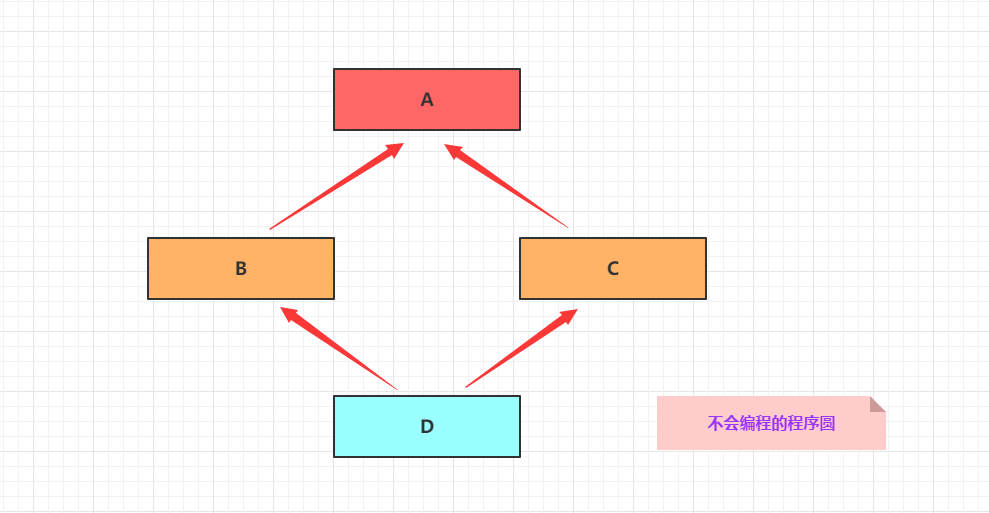
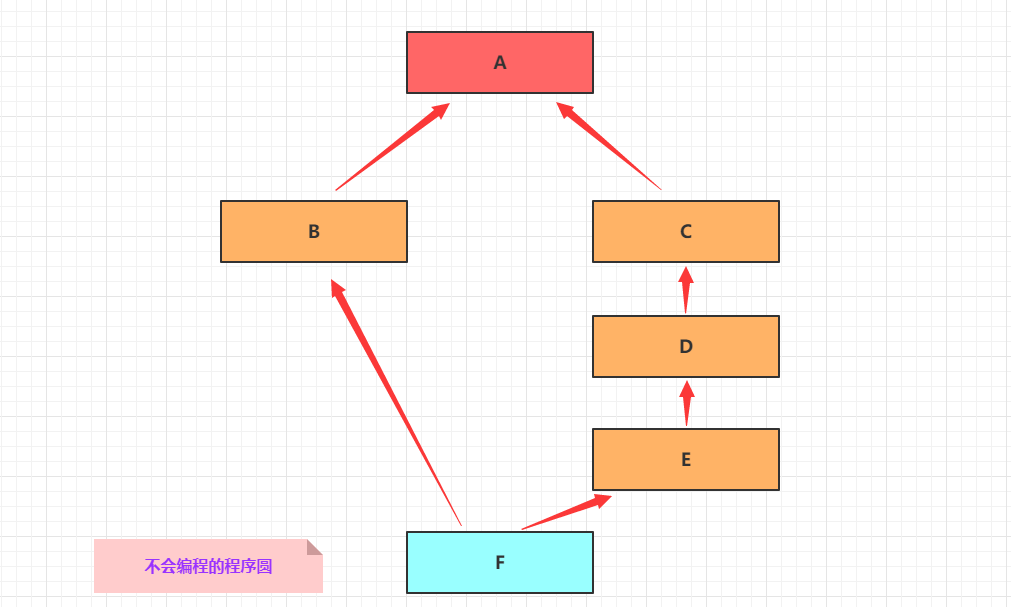
当然菱形继承还可能更加复杂,比如:
第一种菱形继承中,类 D 的大小是多少?
void test5()
{
D d;
cout << "sizeof(D) = " << sizeof(D) << endl; // 20
}
可以看到,类 D 的大小是 20(字节)。
这里 D 的大小是 20,是因为 D 中存在两份 A 类中的 _a 成员。因为 B,C 都继承了 A 中的 _a,而 D 继承了 B,C ,因此 D 继承了两份 _a 。
如果访问 d._a ,到底访问的是父类中哪一个类继承的 _a 呢?在编译器警告级别较高的情况下,这样写是不能通过编译的。
我们需要指定继承自哪一个父类的 _a :
d.B::_a = 0xaa;
这里我们可以打开 VS 2019 的内存监视器(打开方式: 调试 -> 窗口 -> 内存 )中,查看这 5 个成员在对象 d 内存中的布局:

为什么从 B 继承来的成员会在 d 对象内存的头部呢?
我们都知道在子类对象的内存中,从父类继承来的成员放在内存的头部(这个规律保证了切片这一操作)。因为继承时,我们先写的是 public B 所以 从 B 继承来的成员就在头部。如果我们写成:
class D : public C, public B
那么,可以看到:

菱形虚拟继承
因为菱形继承带来的 冗余性 和 二义性 ,为了解决这个问题,就有了菱形虚拟内存的概念。
class A
{
public:
int _a = 0xa;
};
class B : virtual public A
{
public:
int _b = 0xb;
};
class C : virtual public A
{
public:
int _c = 0xc;
};
class D : public C, public B
{
public:
int _d = 0xd;
};
在可能会造成冗余的 B,C 类继承 A 类时,加上 virtual 关键字
这时,我们再来看 D 类型的大小:
void test5()
{
D d;
cout << "sizeof(D) = " << sizeof(D) << endl; // 24
}
d 竟然变成了 24(字节)?!
占用内存不降反而多了是我没想到的,为什么会这样呢?先不要着急,我们再看一个例子:
我们把所有类的成员类型换成 string,我们知道 string 类型的初始大小为 28 。然后再来看 D 类型 d 的大小是多少。我们知道,如果没有虚拟继承,d 的大小将是 28 x 5 = 140 (字节)
class A
{
public:
string _a;
};
class B : virtual public A
{
public:
string _b;
};
class C : virtual public A
{
public:
string _c;
};
class D : public C, public B
{
public:
string _d;
};
void test5()
{
D d;
cout << "sizeof(string) = " << sizeof(string) << endl; // 28
cout << "sizeof(D) = " << sizeof(D) << endl; // 120:28 x 4 + 4 x 2
}
D 的实际大小是 28 * 4 + 4 * 2
4 * 2 是什么?它代表两个 虚基表指针
虚基表指针和虚基表
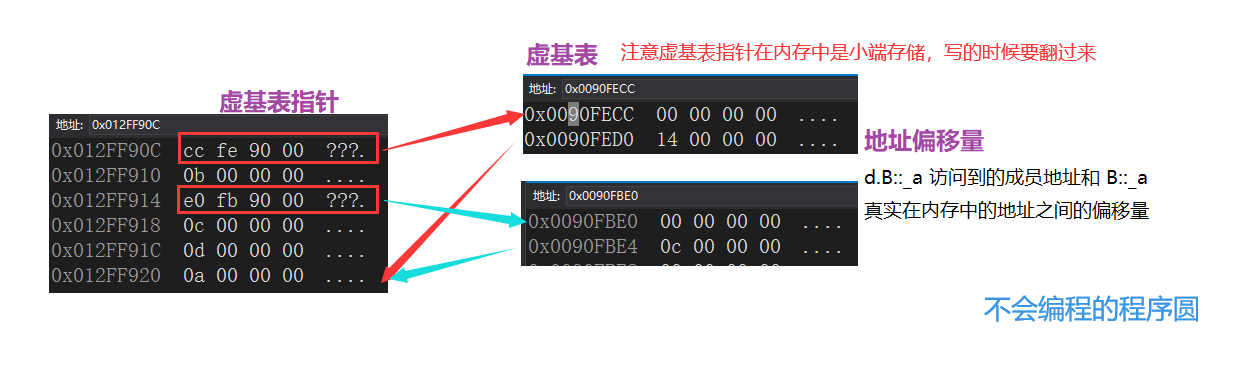
虚基表指针在对象中,而虚基表不在对象中
对应关系:
3. 多态
其他
0. 浅拷贝与深拷贝
浅拷贝
// 理解什么是浅拷贝
// 浅拷贝指的是在我们复制一个对象时,对象内的资源并没有同时复制一份,只是简单的让新的指针指向了旧的内容
#include<iostream>
#include<string.h>
#include<stdlib.h>
#include<stdio.h>
using namespace std;
class Age
{
public:
Age(const char* name, int age)
{
_age = age;
_name = name;
}
// 默认赋值构造
void print()
{
cout << _name << " " << _age << endl;
}
void print_address()
{
printf("%p\n", _name);
}
// 我们可以看到,两个对象的 _name 中存放的内容是一样的,也就是那个字符串 "Shepard"
// 这就是一种浅拷贝,但是其实这里我们并没有用到拷贝构造,请到 test5.cpp 中进一步查看拷贝构造的情况
private:
const char* _name;
int _age;
};
int main(void){
Age n1("Shepard", 20);
Age n2(n1);
n2.print();
n1.print_address();
n2.print_address();
return 0;
}
深拷贝
// 理解什么是浅拷贝
// 浅拷贝指的是在我们复制一个对象时,对象内的资源并没有同时复制一份,只是简单的让新的指针指向了旧的内容
#include<iostream>
#include<string.h>
#include<stdlib.h>
#include<stdio.h>
using namespace std;
class Age
{
public:
Age(const char* name, int age)
{
_age = age;
// 申请资源
_name = (char*)malloc(sizeof(char) * (strlen(name) + 1));
strcpy(_name, name);
}
Age(const Age& a)
{
_name = (char*)malloc(sizeof(char) * (strlen(a._name) + 1));
strcpy(_name, a._name);
}
// 我们先把我们写的拷贝构造函数注释起来,调用系统默认的拷贝构造函数
// 发现:两个对象的成员 _name 指向的内容是一样的
// 然后取消注释
// 发现:两个对象的成员 _name 指像了不同的内容,这就说明,对象 1 中的资源也被对象 2 拷贝了一份
// 这就是深拷贝
void print()
{
cout << _name << " " << _age << endl;
}
void print_address()
{
printf("%p\n", _name);
}
private:
char* _name;
int _age;
};
int main(void){
Age n1("Shepard", 20);
Age n2(n1);
n2.print();
n1.print_address();
n2.print_address();
return 0;
}
1. 编译器优化【匿名对象作为拷贝构造函数的形参】的情况
// 使用匿名对象作为拷贝构造的参数
// 本来应该先构造匿名对象,然后拷贝构造该对象
// 但是编译器可能进行优化,跳过匿名对象的构造,直接用匿名对象的参数构造该对象
#include<iostream>
#include<string.h>
#include<stdlib.h>
using namespace std;
class Age
{
public:
Age(int age = 10)
{
this->_age = age;
cout << "Age() " << age << endl;
}
Age(const Age& a)
{
_age = a._age;
cout << "Age(&) " << endl;
}
void print()
{
cout << _age << endl;
}
~Age()
{}
private:
int _age;
};
int main(void){
Age n2(Age(20));
n2.print();
return 0;
}
还有一种情况,编译器也会进行优化:
class Date{
// 我们经常写的 Date 类
};
Date func(){
Date d;
return d;
// 返回类型为 Date,值传递也会产生一个临时变量
// 本来应该产生一个匿名对象,然后再通过拷贝构造构造 main 中的对象 d
// 编译器优化跳过了产生匿名对象这一步,直接用 func 中的 d 拷贝构造 main 中的 d
}
int main(void)
{
Date d(func()); //
}
2. 拷贝构造 与 赋值运算符重载的区别
为什么面 func 返回的时候调用的是 Date 的拷贝构造而不是赋值运算符重载?
虽然拷贝构造和赋值运算符重载看起来是一样的:
Date(const Date& d)
{
_year = d._year;
_month = d._month;
_day = d._day;
}
Date& operator=(Date& d)
{
_year = d._year;
_month = d._month;
_day = d._day;
return *this;
}
但是这两种函数的意义不同:
- 拷贝构造是用一个已经存在的对象构建一个还没有被创建出来的对象
- 赋值运算符重载 的两个操作数都是已经创建好的对象
由此我们可以知道:
int main(void)
{
Date d1;
Date d2 = d1; // 此处调用的是拷贝构造而不是赋值运算符重载
}
3. 为什么拷贝构造函数的定义中形参前需要加上 const
比如日期类 Date 的拷贝构造函数,我们一般写成这样:
Date(const Date& d)
{
_year = d._year;
_month = d._month;
_day = d._day;
}
为什么要加一个 const 呢?
前面我们在学引用的时候说过,临时变量需用用 const 引用来引用。什么是临时变量呢?比如:
double a = 3.1;
int& b = a;
这项写是会报错的,而这样写:
double a = 3.1;
const int& b = a;
才正确
这是因为,double 类型的变量 a 在隐式类型转换后产生一个临时变量。(什么是临时变量?请看这篇博客)
修改临时变量一般是没有意义的(比如上面的 a 隐式类型转换后可能在栈上产生了一个 int 型的变量,我们姑且叫它 aa,b 相当于是 aa 的引用,你通过 b 去改 aa 有什么意义呢?aa 什么也不是),所以用 const 来限制用户修改这个引用指向的变量。
const 引用可以用来引用匿名对象
而且,const 引用也可以引用 非 const 对象,比如:
int b;
const int& c = b;
题外话:关于 volatile
请看下面的程序你觉的会输出什么:
#include<stdio.h>
int main(void)
{
const int a = 10;
int* pa = (int*)&a;
*pa = 20;
printf("%d\n", a);
printf("%d\n", *pa);
return 0;
}
这其实是一个很有趣的问题,细心的朋友可能会发现:上面的代码格式并没有指明(应该会没有高亮吧,我们没有指明是哪一种语言,不过具体还是要看编辑器)
那么,如果你将这段代码用 gcc 或 g++ (以 .c 格式 或以 .cpp 格式)编译运行,结果是不一样的。
如果你用 C 语言的编译器,结果会是 20 20 ;如果是 C++ 的编译器的话,结果就是 10 20
C 语言的结果我们不难理解,因为 pa 改变了 a 的内容。但是为什么 C++ 的结果会是10 和 20 呢?难道 pa 指向的不是 a ?
其实 pa 指向的就是 a,而且 a 的值也被改为了 20 。但是,C++ 的编译器做了优化:因为你不是声明 a 是 const 类型的了吗,当要用到 a 的时候,编译器没有从 a 标识的内存中读取值,而是直接从寄存器(或者缓存)中读取。而在那里,存放的是常量 10 。
如何让编译器不做优化,而是“老老实实”地从内存中读取 a 呢?就是把 a 声明为 volatile ,这个单词是易变的的意思。
const volatile int a = 10;
4. + 运算符重载后,我发现 d + 1 可以 1 + d 却不可以,怎么解决?
Date operator+(int day)
{
Date ret = *this;
ret += day;
return ret;
}
cout << (d + 1) << endl; // ok
cout << (1 + d) << endl; // error
其实这个问题和我们对 ostream 和 istream 的重载的原因是一样的。就是因为 this 指针是成员函数默认的第一个参数,而第一个参数默认在运算符的左侧。
因此,如果你用 (1 + d) 的话,第一个参数就成了 1 而不是指向 d 的 this 指针。
解决办法就是使用友元在类外重载 operator+ :
class Date
{
friend Date operator+(int day, Date& d);
...
};
// 类外
Date operator+(int day, Date& d)
{
return (d + day);
}
5. 为什么最好在初始化列表中初始化类类型的成员而不是在构造函数体内初始化?
- 首先,如果这个类类型没有默认构造,必须在初始化列表中进行初始化
- 即使这个类有默认构造,初始化列表中依然会调用类类型成员的构造函数,完成对象的初始化
所以,初始化列表是绕不开的,俗话说的好:“反抗不了,不如闭眼享受”。
而且,要知道,这样写是错误的:
class Time {
public:
Time(int hour = 11)
{
_hour = hour;
cout << "Time() " << _hour << endl;
}
private:
int _hour;
};
class Date {
public:
Date()
{
_t(12); // 不能再次调用构造函数,因为初始化列表已经构造过了
}
private:
Time _t;
};
你只能这样写:
_t = Time(12);
// 或者:
_t = 12;
6. 赋值重载和输入输出重载的返回值
ostream& operator<<(ostream& _cout, const Date& d)
{
_cout << d._year << "-" << d._month << "-" << d._day;
return _cout;
}
istream& operator>>(iostream& _cin, Date& d)
{
_cin >> d._year;
_cin >> d._month;
_cin >> d._day;
return _cin;
}
Date& operator=(const Date& d)
{
if (this != &d) {
_year = d._year;
_month = d._month;
_day = d._day;
}
}
我们发现返回类型都是引用,为什么必须返回引用呢?
我们思考一个很简单的问题,C 语言中,我们常会这样写:
a = b = c;
printf("%d\n", a++);
第一个语句的含义是:a = (b = c) 将 c 的值赋给 b,然后将 b 的值赋给 a 。如果赋值运算后,不返回 = 号的左值,那么赋给 a 的是什么?
如果不返回引用类型的话,将生成一个临时变量,对这两条语句也许没有什么问题。但是如果函数会修改传入的参数内容, 比如func(a++),不管是你是传递指针,还是 func 的形参是引用类型,func 改变的都将只是那个临时变量。这个话题其实又和 3 有了交集,如果你不理解临时变量,还是去看 3 中的参考文章。
事实上,上面我说的这种情况是通不过编译的。
// 赋值运算符重载返回普通类型
Date operator=(const Date& d)
{
if (this != &d)
{
_year = d._year;
_month = d._month;
_day = d._day;
}
return *this;
}
Date& fun(Date& d)
{
d--;
return d;
}
int main(void)
{
Date d1(2020, 1, 1);
Date d2;
cout << (fun((d2 = d1))) << endl; // 报错 非常量引用的初始值必须为左值
return 0;
}
编译器不允许修改临时变量
更改的办法也很简单,就是让赋值重载返回引用类型。