
如果这篇博客帮助到你,可以请我喝一杯咖啡~
CC BY 4.0 (除特别声明或转载文章外)
一 string
1. 关于 string 类的扩容
string 类中有两个成员变量:size 和 capacity,size 就是字符串的长度,而 capacity 表示当前对象的字符串可以有多长。
我想 capacity 存在的意义类似于内存池,从而使频繁的小规模的插入不需要每次向堆申请空间(比如 push_back())。
当你在使用 reserve()函数或者其他的方式从而使得 capacity 的大小增加时,实际 capacity 增加后到的值并不会总会如你所愿。它可能会按照固定的大小增容:
| VS 下的扩容 |
|---|
| 16 |
| 32(2 倍) |
| 48(最准的一次 1.5 倍) |
| 71 (1.47 倍) |
| 106 (1.49 倍) |
| 158 (1.49 倍) |
注意: VS 中,你看到的 capacity 的大小不包含字符串结尾的空字符,所以 capacity + 1 才是真正占用的空间。
所以我们在实现中偷个懒,每次扩容 1.5 倍,capacity 初始化 为 15 (申请 16 字节的空间)
这时候还有一个问题:如果调用 C 串的构造函数,如果字符串长度比 15 大,应该怎么设置初始空间的大小?
编译器并不会按照上面的规律设置初始值,但是增容大概总是比理论上应该占用的空间稍微大一些。所以在这块我们就可以自由发挥了。
当然,选择 1.5 倍增容或是 2 倍增容(还是其他的增容策略)并无本质上的区别。
由于看不到 STL string 类的实现,所以我的实现中并没有加入这种每次多扩容的机制,这就导致 capacity 其实并没有什么用。
2. reserve 扩大的 capacity 不会”遗传”
使用 reverse() 扩大对象的 capacity 后,用其创建新的对象时(拷贝构造),新的对象的 capacity 不会”继承“ 其 capacity 的大小。
string str();
str.reserve(100); // [capacity] 111
string str1(str); // [capacity] 15
Tips:最后创建的对象最先销毁(最先调用析构)
3. 浅拷贝 与 深拷贝
从 C 语言的角度,字符串的拷贝就是 strcpy 。使用这个函数的前提是你得准备好两个数组:
char dest[10];
char src[10] = "world";
strcpy(dest, src);
我们发现:拷贝后修改 dest 的内容并不会修改 src 的内容,其实这就是深拷贝的原理。
但是,下面这种方式,修改一个的内容,另一个的内容也会改变:
char* dest;
char src[10] = "world";
dest = src;
strcpy(dest, "123"); // dest, src 的内容发生了改变
相比你也能猜到,这就是浅拷贝了。
其实上面说的“修改一个的内容,另一个的内容也会改变” 并不恰当,应为其实自始至终只有一个数组,dest 只是 src 数组的一个引用罢了。
接下来,我们回到 C++ 。
下面是对构造函数和拷贝构造的实现,你觉得问题会出在哪里:
String(char* s)
:_str(s)
,_size(strlen(s))
,_capacity(_size)
{}
String(const String& str)
:_str(str._str)
,_size(str._size)
,_capacity(str._capacity)
{}
如果你在析构函数中不写对 _str 引用的资源的释放,可能程序并不会报错。
但是如果你在析构中写了对 _str 引用的资源的释放,程序就出错,但是这两个函数出错的方式不一样:
- 如果你是用构造创建的对象,那么析构函数会试图释放一个已经在栈上被释放了的内存
- 如果你调用的拷贝构造,那么会存在多次释放的问题(两个对象的
_str同时引用了堆上同样的内存)
所以,我们应该在创建对象时,同时为 _str 申请一块空间:
// c 风格字符串构造
String(const char* s)
{
_size = strlen(s);
_capacity = _size;
_str = new char[_capacity];
strcpy(_str, s);
}
// 拷贝构造
String(const String& str)
:_str(new char[str._capacity + 1])
,_size(str._size)
,_capacity(str._capacity)
{
strcpy(_str, str._str);
}
4. string 类拷贝构造和赋值运算符重载的现代写法
这是一般我们写拷贝构造的方法:
String(const String& str)
:_str(new char[str._capacity + 1])
,_size(str._size)
,_capacity(str._capacity)
{
strcpy(_str, str._str);
}
现代方法:
// 拷贝构造现代写法,利于代码复用
String(const String& str)
:_str(nullptr)
// 一定要初始化为空,因为交换后 tmp._str 指向本来 this->_str 指向的空间
// 如果 this->_str 没有初始化,临时变量 tmp 被释放时,会调用析构释放 tmp._str
// 也就是本来的(this->_str) 指向的空间,而这个空间是随机的,因此会引发未定义行为
{
// 调用 c 风格构造函数
String tmp(str._str);
Swap(tmp);
// 如果调用内置的 swap(*this, tmp) 传入两个引用,
// 会申请一个临时的 String 类型的变量,然后还会有两次类类型间的赋值,比较低效
}
void Swap(String& tmp)
{
swap(_str, tmp._str);
swap(_size, tmp._size);
swap(_capacity, tmp._capacity);
}
//void Swap(String& str)
//{
// //拷贝构造
// String tmp = str;
// //赋值运算符
// str = *this;
// //赋值运算符
// *this = tmp;
//}
// 赋值运算符重载函数
// 参数值传递,这样参数改变不影响本来的值
String& operator=(String str)
{
Swap(str);
// 不需要调用拷贝构造,因为实参传给形参时就是拷贝构造
return *this;
}
5. 无符号整型作为控制变量
下面是对 String 类中 insert 的一种的实现:
String& insert(size_t pos, const char* s)
{
if(pos <= _size && s != nullptr)
{
size_t len = strlen(s);
if(_size + len > _capacity)
reserve(_size + len);
// 移动 [pos, _size] 的元素到 [pos + len, _size + len]
size_t end = _size + len; // '\0' 也应该移动
// 因为 end 是 size_t(unsigned int) 类型,如果右式 == 0,end 再次自减不会小于 0,这样会造成无限循环
// 解决办法就是在判断表达式中不要出现 = 号
while(end > pos + len - 1)
{
_str[end] = _str[end - len];
end--;
}
for(size_t i = 0; i < len; i++)
{
_str[pos + i] = s[i];
}
_size += len;
}
return *this;
}
因为 end 是无符号整型,如果 while 循环中使用 >= 来判断,当用户要头插(pos 为 0)时,当遍历到 end 为 0 时,下一次自减 end 会变成该类型最大的整数而非预期的 -1 。
解决办法就是在判断表达式中不要出现 = 号
这句话的意思就是:在移动元素时,不要将当前位置的的元素移动到下一位,而应该将下一位元素移动到当前位置。我们现在来看上面的情况,将长度为 len 的 c 字符串 s 插入原字符串 pos 的位置上,也就是说,应该把 pos 到 _size 位置上的元素依次向后移动 len 个位置(_size 位置放的是 \0)
size_t end = _size + len;
// 移动 [pos, _size] 上的元素到 [pos + len, _size + len] 上
while(end > pos + len - 1) // - 1 是为了最后一个元素可以被移动到 pos + len 位置上
{
_str[end] = _str[end - len];
end--;
}
上面是正确的写法,如果你要是用 >= 就是下面这样:
size_t end = _size;
while(end >= pos)
{
_str[end + len] = _str[end];
end--;
}
// 如果 pos == 0,最后会陷入无限循环
6. npos 的判定
下面时 erase 函数的一部分:
String& erase(size_t pos = 0, size_t len = npos)
{
if(pos > _size)
return *this;
if(pos + len >= _size)
{
_str[pos] = '\0';
_size = pos;
}
else
{
...
}
return *this;
}
当我试图这样调用 erase 时:
erase(1);
我发现:程序走的是 else 的部分。但是当缺省 len 时,表示删除 pos 及其之后的所有内容,理应进入 if 部分。
经过思考,我发现:len 此时已经是 size_t 类型的最大值,如果再加上一个数,尤其是像 pos 这样的小数,len 会变成一个很小的数,看看我们对 npos 的定义:
const size_t String::npos = -1;
因此我们将 if 内的判断改为:
if(pos + len >= _size || len == npos)
程序就正确了
7. 类外的函数
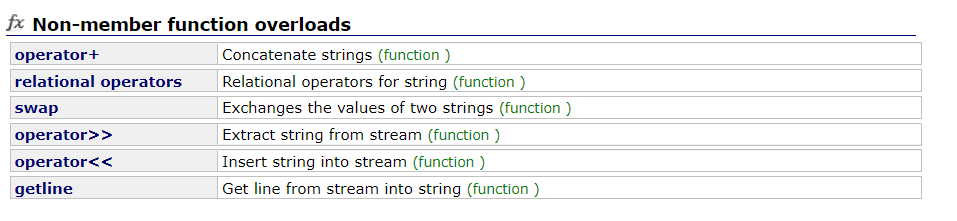
上面这些函数直接实现在类外即可(不需要在类内声明)
8. 关系运算符
C++ 类的关系运算符实质比较的就是 C 字符串,遵循 C 语言 strcmp 的比较规则。
总结
string 类的每个函数的功能看起来都蛮简单的,昨天我有一种错觉:实现 string 类很简单!
结果我花了一整天去实现它,中间 VS 还出了问题,重新生成解决方案,重新创建项目,重启电脑都无法解决,百度也无法找到对应的解答。所以我只得去 linux 下写,由于我 gdb 掌握的不是很好,不能像使用 VS 一样很轻松的调试,所以我就把每个函数用打印的方式直观的对比 string 和我实现的 String 。这种方法确实挺笨的,而且 vim 我也用的不是很 6,这也降低了工作的效率。
昨天晚上遇到 VS 问题 + 代码 bug,一度让我十分消极悲观。今早也没有继续学习 C++,而是看了会其他人的博客和书,算是一种放松吧。但是问题在哪里,我们要有“亮剑精神”,勇敢面对困难。
本来计划昨晚就写完 string 类的实现,结果拖到了今天晚上才完成。耽误的时间,除了怪我自己写代码太少之外,VS 我也是不会放过的!但我并不打算删除 VS 或者到处黑 VS,我要花 1 ~ 2 天好好学习一下 vim,gdb 和 makefile。如果可以的话,从此, vim 就是我写 C++ 的主要工具了。
在实现 string 过程中遇到的一些问题也都记录在了本篇博客中,如果你想看整个代码,请点击下方链接:
二 vector
1. resize 缺省第二个参数
我们来看一下 resize 的定义:
void resize (size_type n, value_type val = value_type());
第二个参数是可以缺省的,缺省时,新增的元素的初始值和类型有关。
比如,int 会初始化为 0;指针会初始化为 nullptr;字符串会初始化为 ""(空串);类类型会调用默认构造初始化(string 类型初始化为空串就是因为调用了它的无参构造)
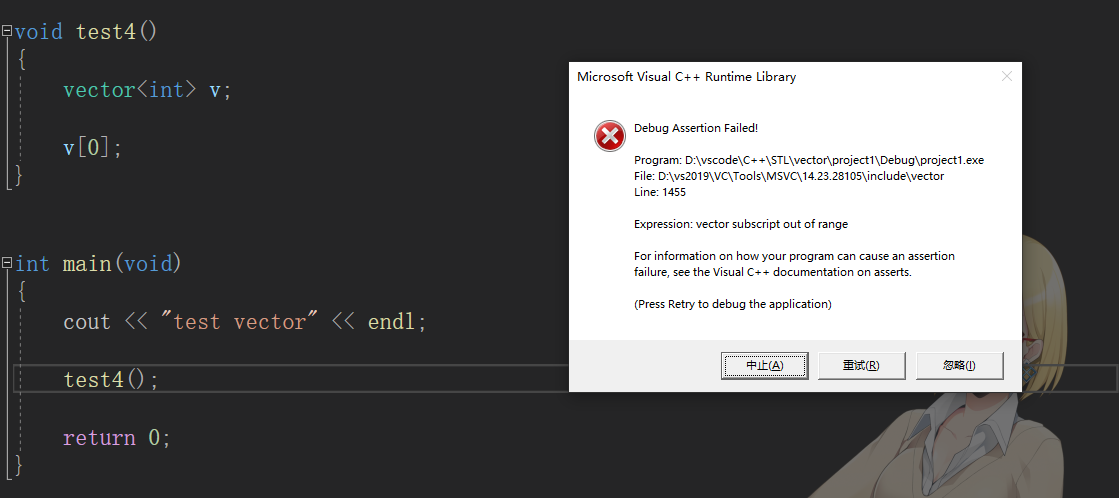
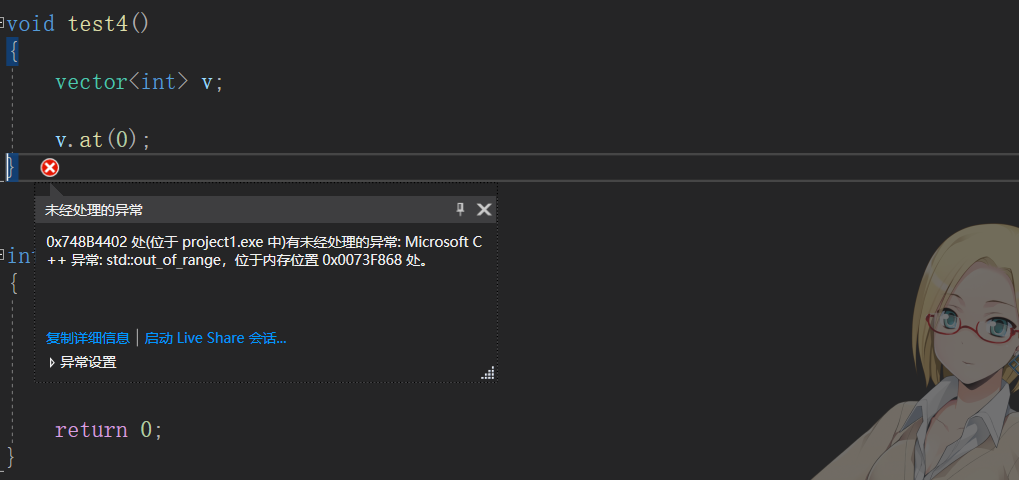
2. operator[] 和 at
operator[] 越界 debug 版本会产生断言; release 版本失效
at 会抛出异常
3. 迭代器失效
如果执行增容操作,迭代器失效
If a reallocation happens, all iterators, pointers and references related to the container are invalidated. Otherwise, only the end iterator is invalidated, and all iterators, pointers and references to elements are guaranteed to keep referring to the same elements they were referring to before the call.
void test5() { vector<int> v(5, 1); cout << v.capacity() << endl; vector<int>::iterator it = v.begin(); v.push_back(2); cout << v.capacity() << endl; // 注释下面这一行,发现 v 的 capacity 发生了变化 cout << *it << endl; // 程序崩溃 }第二句话是说:如果 reallocation 没有发生,只有 end 迭代器失效。其他所有的指向元素的迭代器,指针和引用保证继续引用在调用该函数前相同的元素。
void test7() { vector<int> v(5, 1); cout << v.capacity() << endl; // capacity 为 5 v.reserve(7); // 增容 cout << v.capacity() << endl; // capacity 为 7 vector<int>::iterator it = v.begin(); v.push_back(2); cout << v.capacity() << endl;// capacity 为 7 cout << *it << endl; }只要更行迭代器后没有增容操作,迭代器就不会失效了。
如果执行删除操作,被删除位置及其以后的迭代器失效
Iterators, pointers and references pointing to position (or first) and beyond are invalidated, with all iterators, pointers and references to elements before position (or first) are guaranteed to keep referring to the same elements they were referring to before the call.
void test6() { vector<int> v(5, 1); vector<int>::iterator it = v.begin(); vector<int>::iterator it2 = it + 2; // 删除下标的区间 [1, 2], pos 为 1 v.erase(it + 1, it + 3); // it 指向下标为 0 的位置,在 pos 前,所以迭代器有效 cout << *it << endl; // it2 指向下标为 2 的位置,在 pos 之后,迭代器失效,程序崩溃 cout << *it2 << endl; }
4. 使用函数返回值更新迭代器
观察 erase 函数发现:
iterator erase (iterator position);
iterator erase (iterator first, iterator last);
这个返回值是什么呢:
An iterator pointing to the new location of the element that followed the last element erased by the function call. This is the container end if the operation erased the last element in the sequence.
返回的是一个指向最后一个被删除元素的下一个元素。如果顺序表中最后一个元素被删除,返回 end() 迭代器。
void test8()
{
vector<int> v(5, 1);
vector<int>::iterator it = v.begin();
while (it != v.end())
{
it = v.erase(it); // 更新迭代器
}
}
我们再来看一下 insert 函数:
single element (1)
iterator insert (iterator position, const value_type& val);
fill (2)
void insert (iterator position, size_type n, const value_type& val);
range (3)
template <class InputIterator>
void insert (iterator position, InputIterator first, InputIterator last);
An iterator that points to the first of the newly inserted elements.
第一个函数返回的是指向新插入的首个元素的迭代器
void test9()
{
vector<int> v(5, 1);
vector<int>::iterator it = v.begin();
it = v.insert(it, 2);
cout << *it << endl;
}
关于 erase 的迭代器问题我们可以来看这样一个例子。基于我们自己实现的 erase :
iterator erase(iterator pos)
{
if (pos >= _start && pos < _finish)
{
// 容器无元素或容器为空
if (capacity() == 0 || size() == 0)
return _finish;
iterator begin = pos;
while (begin < _finish - 1)
{
*(begin) = *(begin + 1);
begin++;
}
_finish--;
return pos;
}
else
return _finish;
}
对于 vector<int> 类型的数组,我们要删除其中的奇数或偶数:
Vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.push_back(6);
v.push_back(7);
下面这两种删除方式有错误吗?
// 删除奇数,程序有没有问题?
while (it != v.end())
{
if (*it % 2 != 0)
it = v.erase(it);
it++;
}
v.printVector();
程序崩溃
// 删除偶数呢?
while (it != v.end())
{
if (*it % 2 == 0)
it = v.erase(it);
it++;
}
v.printVector();
输出正确结果
// 思考一下原因
// 其实这和迭代器失效也有关系
// 删除奇数的正确写法:
while (it != v.end())
{
if (*it % 2 != 0)
it = v.erase(it);
// 另外,不更新迭代器在这里也是可以正常编译运行的
// 但是这个前提是迭代器不失效而且容器是顺序表存储的,如果是链表存储,那么这里就是错误的
else
it++;
}
v.printVector();
5. 深拷贝
当你在实现 vector 的时候,一定要考虑如果 vector 的类型是 string 这种含有资源的情况。因此无论是拷贝构造还是 reverse 函数,都需要用循环进行复制而不是这样:
void reserve(size_t n)
{
if (n <= capacity())
return;
int oldSize = size();
// 开空间
T* tmp = new T[n];
// 如果当前容器不为空,拷贝旧空间内容到新空间
if (oldSize != 0)
{
memcpy(tmp, _start, sizeof(T) * oldSize);
}
// 释放空间
delete[] _start;
// 更新
_start = tmp;
_finish = _start + oldSize;
_eos = _start + n;
}
要知道,C++ 的对象大小是不包括资源的,其实 vector 的大小用 sizeof 算出来的只是那几个成员变量(3 个指针)而已。
因此,我们要调用 string 的复制构造来完成深拷贝:
void reserve(size_t n)
{
if (n <= capacity())
return;
int oldSize = size();
// 开空间
T* tmp = new T[n];
// 如果当前容器不为空,拷贝旧空间内容到新空间
if (oldSize != 0)
{
// 如果 T 为 string 类,memset 的拷贝方式不能实现深拷贝。
// memcpy(tmp, _start, sizeof(T) * oldSize);
for (int i = 0; i < oldSize; i++)
{
// 调用 T 类型的赋值运算符
tmp[i] = _start[i];
}
}
//3. 释放原有空间
delete[] _start;
//4. 更新空间指向, 容量
_start = tmp;
_finish = _start + oldSize;
_eos = _start + n;
}
为什么赋值就是深拷贝了?那你去看看我们写的 string 类中的拷贝构造是如何实现的就明白了。
6. 关于模板的诡异报错
提供一个思路:检查函数参数是否应该被 const 修饰或者 this 指针是否应该被 const 修饰。
三 list
### 1. list 迭代器
list 的迭代器并不是一个指针,因为:
list是链表,一个节点的指针自增自减不能保证指向下一个或上一个节点- 对节点的解引用要的是节点内
val成员
因此,我们将 list 迭代器封装成一个类:
/**
* ListIterator: 链表的迭代器
* 类类型的迭代器不是指针,而是一个类。
* 各种操作其实本质是操作 ListNode 中的某个成员
*/
template<class T, class Ref, class Ptr>
struct ListIterator
{
typedef ListNode<T> Node;
typedef ListIterator<T, Ref, Ptr> Self;
ListIterator(Node* node)
:_node(node)
{}
Ref operator*()
{
return _node->_value;
}
/**
* -> 当作单目运算符处理
* 类类型中的元素访问模式:ListNode->_val->某一个元素
* 中间的 ->_val 被编译器优化
*/
Ptr operator->()
{
return &_node->_value;
}
Self& operator++()
{
_node = _node->_next;
return *this;
}
Self& operator--()
{
_node = _node->_prev;
return *this;
}
bool operator!=(const Self& it)
{
return _node != it._node;
}
Node* _node;
};
在 List 中定义这样的类型:
typedef ListIterator<T, T&, T*> iterator;
typedef ListIterator<T, const T&, const T*> const_iterator;
为什么要使用 template<class T, class Ref, class Ptr> 这么复杂的模板?
因为迭代器有 const 与 非const之分,因此,* 和 -> 运算符重载我们需要写两份,但是这样写编译器会出现报错,所以我们采用这种写法。参考下图:

2. list 迭代器的 * 和 -> 运算符
Ref operator*()
{
return _node->_value;
}
* 解引用返回的是迭代器指向的节点的成员_value
Ptr operator->()
{
return &_node->_value;
}
->返回的是 _value 的指针,这个运算符主要针对的是类类型的 list,比如:
class A
{
public:
friend ostream& operator<<(ostream& _o, const A& L);
A(int a = 1, int b = 1)
:_a(a)
,_b(b)
{}
int _a;
int _b;
};
void test4()
{
List<A> L;
L.push_back(A(1, 1));
L.push_back(A(2, 2));
L.push_back(A(3, 3));
List<A>::iterator it = L.begin();
cout << *it << endl;
cout << it->_a << endl;
}
it->_a 这个表达式是不是十分的诡异?因为 it 是一个 iterator 类型而不是指针,并且它也没有 _a 成员。
其实这个表达式的含义是:it.operator->()->_a ,这就是编译器的“功劳”了。
3. list 迭代器 ++ 运算符
typedef ListIterator<T, Ref, Ptr> Self;
Self& operator++()
{
_node = _node->_next;
return *this;
}
注意 ++ 是让迭代器的 _node 成员指向下一个节点,返回当前迭代器的引用。
-- 同理。
4. list 的头节点
list 是双向带头循环链表
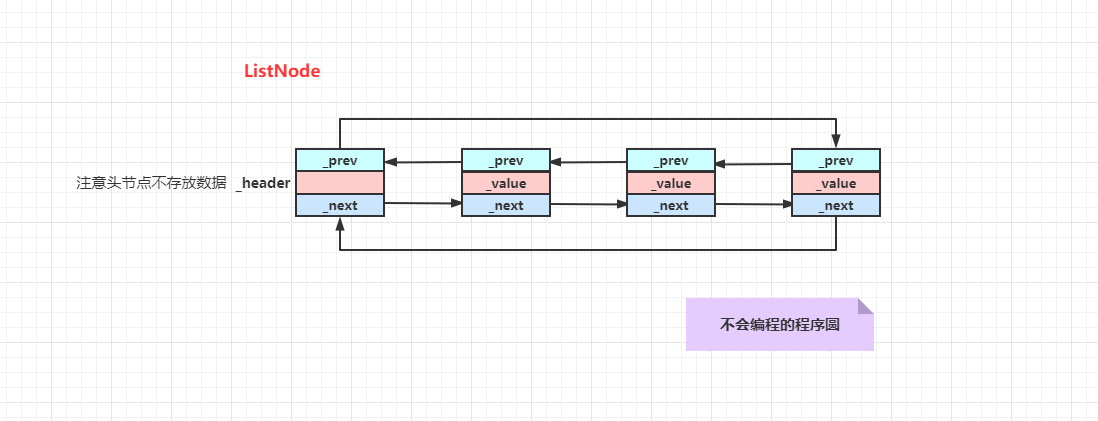
因为头节点的特殊,我们就要小心的处理头节点:
构造函数
List()
:_header(new Node)
{
_header->_next = _header->_prev = _header;
}
构造函数中创建一个头节点,然后让头节点的指针域都指向自身。这样做的好处是,向空表中插入和删除链表最后一个元素时,不需要单独处理这种情况。
这是插入和删除函数:
iterator insert(iterator pos, const T& val)
{
Node* node = new Node(val);
node->_next = pos._node;
node->_prev = pos._node->_prev;
node->_next->_prev = node;
node->_prev->_next = node;
return iterator(node);
}
iterator erase(iterator pos)
{
// 不能删除头节点
if (pos != end())
{
Node* del = pos._node;
Node* next = del->_next;
del->_prev->_next = del->_next;
del->_next->_prev = del->_prev;
delete del;
return iterator(next);
}
return pos;
}
5. list 的拷贝构造和 = 运算符
List(const List<T>& lst)
:_header(new Node)
{
_header->_next = _header->_prev = _header;
//深拷贝,插入元素
for (const auto& e : lst)
push_back(e);
}
// 现代写法
List<T>& operator=(List<T> L)
{
swap(_header, L._header);
return *this;
}
注意深拷贝和现代写法。
6. list 的成员函数 begin()
iterator begin()
{
return iterator(_header->_next);
}
List<A>::iterator it = L.begin();
调试时发现,iterator 类型的构造只进行了一次。begin 返回的是一个 iterator 类型的临时变量,编译器应该进行了优化:List<A>::iterator it(_header->next)
7. it++ or ++it?
Self& operator++()
{
_node = _node->_next;
return *this;
}
template<class T>
void printList(const List<T> L)
{
typename List<T>::const_iterator it = L.begin();
while (it != L.end())
{
cout << it._node->_value << " ";
++it; // 不能写成 it++
}
cout << endl;
}
printList 函数中的 ++it 是不能写成 it++ 的,这是因为你没有重载后置++函数,自己重载一下就行了:
Self& operator++(int)
{
Self ret(*this);
_node = _node->_next;
return ret;
}