
如果这篇博客帮助到你,可以请我喝一杯咖啡~
CC BY 4.0 (除特别声明或转载文章外)
零
模板的声明(declaration)并未给出一个函数或类的完整定义(definition),只是提供了一个函数或类的语法框架(syntactical skeleton)。
实例化是指用具体类型代替模板参数
T的过程。比如
template <typename T>
struct Object
{
};
实例化:
Object<int>;
Object<char*>;
Object<MyClass>;
实例化的两种类型:
- 显示实例化:在代码中明确指定要针对那种类型进行实例化
- 隐式实例化:编译器根据参数类型自动推导
模板被编译两次
- 没有实例化之前,检查模板代码是否有语法错误
- 实例化期间,检查对模板代码的调用是否合法
一 模板函数
1. 使用方法
template <typename/class 参数1, typename / class 参数2 ...>
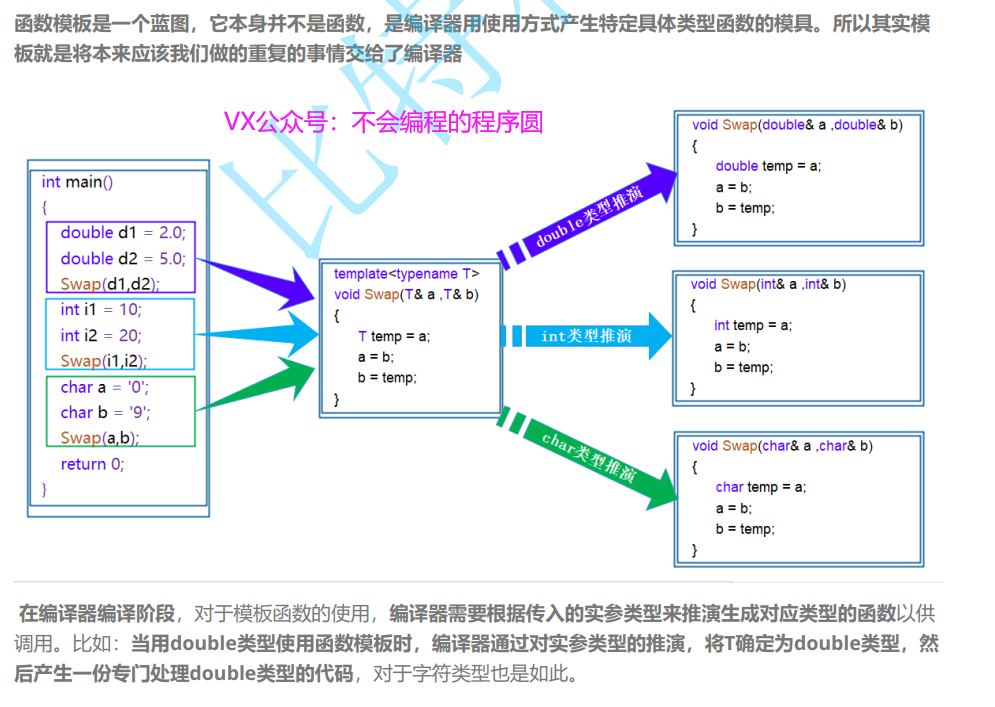
template <class T>
void swap(T& left, T& right)
{
T tmp = left;
left = right;
right = tmp;
}
int main(void){
char c1 = 'a', c2 = 'b';
int i1 = 1, i2 = 2;
swap(c1, c2);
swap(i1, i2);
}
2. 实例化
用不同类型的参数使用函数模板时,称为函数模板的实例化。
1.隐式实例化:让编译器根据实参推演模板参数的实际类型
不允许自动类型转换,每个 T 必须严格匹配
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
Add(a1, a2);
Add(d1, d2);
/*
该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型
通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,
编译器无法确定此处到底该将T确定为int 或者 double类型而报错
注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要背黑锅
Add(a1, d1);
*/
// 此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化
Add(a1, (int)d1);
Add<int>(a1, d1);
Add('a', 20); // 调用非模板函数
short s = 2;
Add(s, a1); // 调用非模板函数
return 0;
}
2.显式实例化:在函数名后的<>中指定模板参数的实际类型
template <class T>
void Swap(T& left, T& right)
{
T tmp = left;
left = right;
right = tmp;
}
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main(void)
{
char c1 = 'a', c2 = 'b';
int i1 = 1, i2 = 2;
Swap(c1, c2);
Swap(i1, i2);
Swap(c1, (char&)i1);
Swap<char&>(c1, (char&)i1);
// 通过打印发现 c1 变了,而 i1 没变,这是因为类型转换生成的了临时对象,传递的引用为临时对象的引用
Add<const char&>(c1, (char&)a1); // 必须显示指定 const char&,只指定 char& 会报错
// 我个人分析的原因:Add 函数返回的是个临时对象,由于显示指定的返回值类型为引用类型,必须用 const 引用引用临时对象
}
不使用引用:
template <class T>
void Swap(T left, T right)
{
T tmp = left;
left = right;
right = tmp;
}
Swap(c1, (char)i1);
Swap<char>(c1, i1); // ok
3. 函数模板特化
template<class T>
T Add(T& t1, T& t2)
{
return t1 + t2;
}
/**
* 函数模板特化
* const char*& t1 这个 & 符号必须要写,要和模板保持一致
*/
template<>
char* Add<char*>(char*& t1, char*& t2)
{
char* ret = new char[strlen(t1) + strlen(t2) + 1];
strcpy(ret, t1);
strcat(ret, t2);
return ret;
}
.
/**
* 特化写起来很麻烦,我们可以直接定义一个 char* 专属的 Add 函数,
* 编译器依然优先调用此函数
*/
char* Add(char* t1, char* t2)
{
char* ret = new char[strlen(t1) + strlen(t2) + 1];
strcpy(ret, t1);
strcat(ret, t2);
return ret;
}
###
4. 实例化和具体化的区别
具体化我们前面提过,它的含义是:
不要使用
Swap()模板来生成函数,而应该使用独立的,专门的函数定义显示的为 job 类型生成函数定义
实例化(instantiation)
编译器为特定类型生成函数定义时,得到的是模板实例。
Swap(a, b) 这类成为隐式实例化(implicit instantiation)
而显示实例化(explict instantiation)为 Swap<int>(a, b)
隐式实例化,显示实例化,显示具体化统称为具体化(specialization)。他们的共同之处在于:他们表示的都是使用具体类型的函数定义,而不是通用描述
编译器选择使用那个函数版本
对于函数重载,函数模板和函数模板重载,C++ 需要(且有)一个定义良好的策略,来决定为函数调用提供哪一个函数定义,尤其是多个参数时。这个过程称为 重载解析 (overloading resolution)。
可行函数最佳到最差:
- 完全匹配。但常规函数优于模板
- 提升转换。(例如,char,short 转换为 int;float 转换为 double)
- 标准转换。(例如,int 转换为 char,long 转换为 double)
- 用户定义的转换。
完全匹配允许的无关紧要的转换:(Type 表示任意类型)
| 从实参 | 到形参 | 从实参 | 到形参 |
|---|---|---|---|
Type | Type& | Type | const Type |
Type& | Type | Type | volatile Type |
Type[] | Type* | Type* | const Type* |
Type(argument-list) | Type(*) (argument-list) | Type* | volatile Type* |
对于模板函数来说:
graph LR
A["非模板函数"] -- 优于 --> B["显式具体化"] -- 优于 --> C["隐式生成的模板"]
最具体 (most specialized)是指编译器推断使用哪种类型时执行的转换最少。
例如:
// 模板 1
template<class T>
void recycle(T t);
// 模板 2
template<class T>
void recycle(T* t);
int a = 10;
recycle(&a);
recycle(&a) 调用与模板 1 匹配,T 被解释为 int*;若与模板 2 匹配,T 被解释为 int
可见,模板 2 是更为 ”具体“ 的,因为在生成的过程中,它需要进行的转换更少。
总结:
简而言之,重载解析将寻找最匹配的函数。如果只存在一个这样的函数,则选择它;如果存在多个这样的函数,但其中只有一个是非模板函数,则选择该函数;如果存在多个适合的函数,并且它们都为模板函数,但其中有一个函数比其他函数更具体,则选择该函数。
如果有多个同样合适的非模板函数或模板函数,但没有一个函数比其他函数更具体,则函数调用将是不确定的,因此是错误的。当然,如果不存在匹配的函数,则也是错误的。
二 模板类
声明
const size_t DefaultSize = 100;
template<class T, size_t n = DefaultSize>
class Stack
{
};
- 模板实参可以是整型或
enum - n 可以有默认值
eg:
#include<iostream>
using namespace std;
template<class T1, class T2, class T3>
class Date
{
public:
Date(T1 year, T2 month, T3 day)
:_year(year)
,_month(month)
,_day(day)
{}
void print();
private:
T1 _year;
T2 _month;
T3 _day;
};
template<class T1, class T2, class T3> // 类外实现类的成员函数需要加上泛型的声明,相当于一个模板函数
void Date<T1, T2, T3>::print() // 作用域为 类型+泛型名
{
cout << _year << _month << _day << endl;
}
int main(void)
{
// 模板类不能隐式实例化
// Date d;// use of class template 'Date' requires template arguments
Date<int, int, int>d(2020, 6, 20);
d.print();
return 0;
}
成员函数实现
const size_t DefaultSize = 100;
template<class T, size_t MaxSize = DefaultSize>
class Stack
{
void push(const T& val);
};
template<class T, size_t MaxSize>
void Stack<T, MaxSize>::push(const T &val)
{
}
使用类模板
Stack<int> s1;
Stack<int, 200> s2;
特化
1. 非类型模板参数
/**
* 模板参数:
* - 非类型模板参数
* 1. 浮点数、类对象以及字符串是不允许作为非类型模板参数的。
* 2. 非类型的模板参数必须在编译期就能确认结果。
* - 类型模板参数
*/
template<class T, size_t N = 10>
class Array
{
private:
T _array[N];
};
2. 全特化与偏特化
/**
* 类模板特化
* 全特化
* 偏特化
*/
template<class T1, class T2>
class B
{
public:
B()
{
cout << "<class T1, class T2>" << endl;
}
};
// 全特化
template<>
class B<int, double>
{
public:
B()
{
cout << "<int, double>" << endl;
}
};
// 偏特化:部分特化
template<class T1>
class B<T1, double>
{
public:
B()
{
cout << "<T1, double>" << endl;
}
};
// 偏特化:限制模板
template<class T1, class T2>
class B<T1&, T2&>
{
public:
B()
{
cout << "<T1&, T2&>" << endl;
}
};
测试:
void test1()
{
int a = 1, b = 2;
int rst1 = Add(a, b);
char* p1 = new char[7];
char* p2 = new char[6];
strcpy(p1, "Hello ");
strcpy(p2, "World");
char* rst2 = Add(p1, p2);
}
void test2()
{
B<char, string> b1;
B<int, double> b2;
B<char, double> b3;
B<char&, string&> b4;
}
注意
1)类模板特化无法特化整型参数
template<class T, size_t MaxSize = 200>
class Stack<T*, MaxSize>
{
};
error: default template arguments may not be used in partial specializations
2)如果有不止一个偏特化同等程度地版本能够匹配某次实例化,则该实例化具有二义性,编译器会报错
template<class T1, class T2>
class Test
{
};
template<class T>
class Test<T, T>
{
};
template<class T1, class T2>
class Test<T1*, T2*>
{
};
int main()
{
Test<int*, int*> t1; //error: 第一个特化版本更加贴合参数个数(相同的参数),第二个特化版本更加贴合类型(int* 变为 int)
Test<int*, double*> t2; // ok
Test<int, int> t3; // ok
return 0;
}
3)默认模板实参
template<typename T, typename TContainer = std::vector<T>>
class Stack
{
};
Stack<int>;
Stack<int, std::list<int>>;
三 分离编译
什么是分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
模板的分离编译
// a.h
template<class T>
T Add(const T& left, const T& right);
// a.cpp
template<class T>
T Add(const T& left, const T& right) {
return left + right;
}
// main.cpp
#include"a.h"
int main()
{
Add(1, 2);
Add(1.0, 2.0);
return 0;
}

将声明和定义放到一个文件
xxx.hpp里面或者xxx.h其实也是可以的。推荐使用这种。模板定义的位置显式实例化。这种方法不实用,不推荐使用。
// a.h
template<class T>
T Add(const T& left, const T& right) {
return left + right;
}
// main.cpp
#include"a.h"
int main()
{
Add(1, 2);
Add(1.0, 2.0);
return 0;
}
总结
【优点】
模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
增强了代码的灵活性
【缺陷】
模板会导致代码膨胀问题,也会导致编译时间变长
出现模板编译错误时,错误信息非常凌乱,不易定位错误
