
如果这篇博客帮助到你,可以请我喝一杯咖啡~
CC BY 4.0 (除特别声明或转载文章外)
零 项目结构

一 日志篇
可变参数宏与 __VA_ARGS__ 宏
当我们想使用可变参数作为函数参数时,如果直接调用,规则很简单,只需要在将函数定义和声明的最后一个参数换为 ... 即可:
调用端:
logMessage(ERROR, MODE, "Today is %d day of Sep. %s!", 3, "\n");
函数定义:
void logMessage(const char* level, int debugMode, const char* format, ...)
{
}
可是,如果我们想要使用宏中使用可变参数呢?下面是使用的规则:
LOGMESSAGE(ERROR, MODE, "Today is %d day of Sep. %s!", 3, "\n");
#define LOGMESSAGE(error_code, debug_mode, format, args...)\
logMessage(__LINE__, __FILE__, #error_code, debug_mode, format, args)
static inline
void logMessage(int line, const char* file, const char* level,
int debugMode, const char* format, ...)
{
}
与可变参数函数不同的是,可变参数宏中的可变参数必须至少有一个参数传入,不然会报错,为了解决这个问题,需要一个特殊的 “##” 操作,如果可变参数被忽略或为空,“ ## ” 操作将使预处理器( preprocessor )去除掉它前面的那个逗号:
#define LOGMESSAGE(error_code, debug_mode, format, args...)\
logMessage(__LINE__, __FILE__, #error_code, debug_mode, format, ##args)
参考文章:
[C/C++ 可变参数宏与 __VA_ARGS__ 宏_c++ __va_args___](
二 HTTP 报文格式
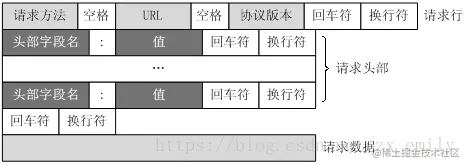
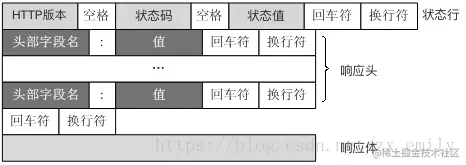
三 MSG_PEEK
当 recv 函数使用 MSG_PEEK 作为第四个参数时,允许调用者从 socket 的输入缓冲中窥探数据,而非将数据从缓冲区中拿出。
如果 recv 返回 0,表示输入缓冲中没有数据!
char buffer[1024];
// Peek at data in the input buffer
ssize_t bytes_peeked = recv(sockfd, buffer, sizeof(buffer), MSG_PEEK);
if (bytes_peeked == 0) {
printf("Input buffer is empty\n");
} else if (bytes_peeked == -1) {
perror("recv");
} else {
// Process the peeked data (without removing it from the buffer)
printf("Peeked data: %.*s\n", (int)bytes_peeked, buffer);
}
四 HTTP GET 和 POST 区别
GET
GET方法请求一个指定资源的表示形式,使用GET的请求应该只被用于获取数据
POST
POST方法用于将实体提交到指定的资源,通常导致在服务器上的状态变化或副作用
本质上都是TCP链接,并无差别
区别:
从w3schools得到的标准答案的区别如下:
- GET 在浏览器回退时是无害的,而 POST 会再次提交请求。
- GET 产生的 URL 地址可以被 Bookmark,而 POST 不可以。
- GET 请求会被浏览器主动 cache,而 POST 不会,除非手动设置。
- GET 请求只能进行 url 编码,而 POST 支持多种编码方式。
- GET 请求参数会被完整保留在浏览器历史记录里,而 POST 中的参数不会被保留。
- GET 请求在 URL中传送的参数是有长度限制的,而 POST 没有。
- 对参数的数据类型,GET 只接受 ASCII 字符,而 POST 没有限制。
- GET 比 POST 更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET 参数通过 URL 传递,POST 放在 Request body 中
参数位置
貌似从上面看到GET与POST请求区别非常大,但两者实质并没有区别
无论 GET 还是 POST,用的都是同一个传输层协议,所以在传输上没有区别
当不携带参数的时候,两者最大的区别为第一行方法名不同
POST /uri HTTP/1.1 \r\n
GET /uri HTTP/1.1 \r\n
当携带参数的时候,我们都知道GET请求是放在url中,POST则放在body中
GET 方法简约版报文是这样的
GET /index.html?name=qiming.c&age=22 HTTP/1.1
Host: localhost
POST 方法简约版报文是这样的
POST /index.html HTTP/1.1
Host: localhost
Content-Type: application/x-www-form-urlencoded
name=qiming.c&age=22
注意:这里只是约定,并不属于HTTP规范,相反的,我们可以在POST请求中url中写入参数,或者GET请求中的body携带参数
参数长度
HTTP 协议没有Body和 URL 的长度限制,对 URL 限制的大多是浏览器和服务器的原因
IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持
这里限制的是整个URL长度,而不仅仅是参数值的长度
服务器处理长 URL 要消耗比较多的资源,为了性能和安全考虑,会给 URL 长度加限制
安全
POST 比 GET 安全,因为数据在地址栏上不可见
然而,从传输的角度来说,他们都是不安全的,因为 HTTP 在网络上是明文传输的,只要在网络节点上捉包,就能完整地获取数据报文
只有使用HTTPS才能加密安全
数据包
对于 GET 方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据)
对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok
并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次
五 thread_pool 单例对象为何使用 shared_ptr
单例对象可以使用原生指针,比如 TcpServer 单例对象:
class TcpServer
{
private:
static TcpServer* _tcp;
};
TcpServer* TcpServer::_tcp = nullptr;
TcpServer* tcp = TcpServer::GetInstance(_port);
由于现代 C++ 要求尽量摆脱对原生指针的直接使用,我们考虑使用智能指针,那么究竟该使用 std::unique_ptr 还是 std::shared_ptr呢?
由于 std::unique_ptr 的赋值运算符和构造函数只保留了右值引用版本。也就是说,如果一个用户拿走了这个单例对象,这个单例对象就会变成空。当下一个用户获取单例时,单例会被重新构造,那么就失去了单例的本来目的。
所以我们采用 std::shrard_ptr ,确保普通的构造和赋值运算符可以被正常调用:
thread_pool.hpp
template<class Task>
class ThreadPool
{
private:
static std::shared_ptr<ThreadPool<Task>> _threadpool;
}
template<class Task>
std::shared_ptr<ThreadPool<Task>> ThreadPool<Task>::_threadpool = nullptr;
http_server.hpp
std::shared_ptr<ThreadPool<HttpTask>> thread_pool = ThreadPool<HttpTask>::GetInstance();
六 recv 和 send 在发送大页面时的技巧
由于 request body 的大小可能很大,我们定义的缓冲区只有 1024 字节,所以需要分批多次读取
char buffer[1024];
size_t read = 0, left = total;
size_t buffer_size = sizeof(buffer) - 1;
int recv_num = 0;
// 注意接受的字节数应该是缓冲区 buffer 大小与剩余待读取字节数的较小值
while( (read < total) &&
(( recv_num = recv(sock, buffer, std::min(buffer_size, left), 0) ) > 0) )
{
buffer[recv_num] = '\0';
*out += buffer;
read += recv_num;
left -= recv_num;
}
由于 block 的大小可能很大,所以我们将其拆分,一次最多发送 4096 字节,分批发送。
const char* buf = block.c_str();
size_t total = block.size();
size_t sent = 0;
ssize_t cnt;
// cnt = send(sock, buf + sent, total - sent, 0);
while( (sent < total) && ( (cnt = send(sock, buf + sent, std::min(4096UL, total - sent), 0)) > 0 ) )
sent += cnt;
sendfile
sendfile 系统调用在两个文件描述符之间直接传递数据(完全在内核中操作),从而避免了数据在内核缓冲区和用户缓冲区之间的拷贝,操作效率很高,被称之为零拷贝。
sendfile系统调用利用 DMA 引擎将文件数据拷贝到内核缓冲区,之后数据被拷贝到内核socket缓冲区中- DMA 引擎将数据从内核
socket缓冲区拷贝到协议引擎中
这里没有用户态和内核态之间的切换,也没有内核缓冲区和用户缓冲区之间的拷贝,大大提升了传输性能。
带有 DMA 收集拷贝功能的 sendfile
上面介绍的 sendfile() 技术在进行数据传输仍然还需要一次多余的数据拷贝操作,通过引入一点硬件上的帮助,这仅有的一次数据拷贝操作也可以避免。为了避免操作系统内核造成的数据副本,需要用到一个支持收集操作的网络接口。
主要的方式是待传输的数据可以分散在存储的不同位置上,而不需要在连续存储中存放。这样一来,从文件中读出的数据就根本不需要被拷贝到 socket 缓冲区中去,而只是需要将缓冲区描述符传到网络协议栈中去,之后其在缓冲区中建立起数据包的相关结构,然后通过 DMA 收集拷贝功能将所有的数据结合成一个网络数据包。网卡的 DMA 引擎会在一次操作中从多个位置读取包头和数据。
Linux 2.4 版本中的 socket 缓冲区就可以满足这种条件,这种方法不但减少了因为多次上下文切换所带来开销,同时也减少了处理器造成的数据副本的个数。对于用户应用程序来说,代码没有任何改变。
过程:
首先,sendfile() 系统调用利用 DMA 引擎将文件内容拷贝到内核缓冲区去;然后,将带有文件位置和长度信息的缓冲区描述符添加到 socket 缓冲区中去,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,DMA 引擎会将数据直接从内核缓冲区拷贝到协议引擎中去,这样就避免了最后一次数据拷贝。
1.传统I/O 硬盘—>内核缓冲区—>用户缓冲区—>内核socket缓冲区—>协议引擎
2.sendfile 硬盘—>内核缓冲区—>内核socket缓冲区—>协议引擎
3.sendfile( DMA 收集拷贝) 硬盘—>内核缓冲区—>协议引擎
七 putenv 和 getenv
int putenv(const char * string);
函数说明:putenv() 用来改变或增加环境变量的内容. 参数string 的格式为 name=value, 如果该环境变量原先存在, 则变量内容会依参数string 改变, 否则此参数内容会成为新的环境变量.
返回值:执行成功则返回 0, 有错误发生则返回 -1.
错误代码:ENOMEM 内存不足, 无法配置新的环境变量空间.
#include <stdlib.h>
main()
{
char *p;
if((p = getenv("USER")))
printf("USER =%s\n", p);
putenv("USER=test");
printf("USER+5s\n", getenv("USER"));
}
char * getenv(const char *name);
函数说明:getenv() 用来取得参数 name 环境变量的内容. 参数 name 为环境变量的名称, 如果该变量存在则会返回指向该内容的指针。环境变量的格式为 name=value.
返回值:执行成功则返回指向该内容的指针,找不到符合的环境变量名称则返回 NULL.
#include <stdlib.h>
int main()
{
char *p;
if((p = getenv("USER")))
printf("USER = %s\n", p);
}
八 统一 write/send 和 read/recv 接口
以 write 和 send 为例,
ssize_t write(int fd, const void *buf, size_t count);
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
除了 send 多一个参数,其余的函数参数形式完全一样,而通常我们将 send 设置为 0
而以网络发送一块数据的 SendBlock() 和 向管道中写入数据的 WritePipe() 在实现上也大致相同
static bool SendBlock(int sock, const std::string& block)
static bool WritePipe(int fd, const std::string& block)
为了最大限度的让函数复用,我们考虑将 SendBlock 和 WritePipe 进一步进行封装,使得底层可以相同的接口调用这两个函数的公共代码 —— WriteBlockToBuffer。
std::bind
std::bind 函数有两种函数原型,定义如下:
template< class F, class... Args >
/*unspecified*/ bind( F&& f, Args&&... args );
template< class R, class F, class... Args >
/*unspecified*/ bind( F&& f, Args&&... args );
std::bind 返回一个基于f的函数对象,其参数被绑定到 args上。 f 的参数要么被绑定到值,要么被绑定到 placeholders(占位符,如 _1, _2, ..., _n)。
std::bind 将可调用对象与其参数一起进行绑定,绑定后的结果可以使用 std::function 保存。std::bind 主要有以下两个作用:
- 将可调用对象和其参数绑定成一个仿函数;
- 只绑定部分参数,减少可调用对象传入的参数。
1)std::bind 绑定普通函数
double callableFunc (double x, double y) {return x/y;}
auto NewCallable = std::bind (callableFunc, std::placeholders::_1,2);
std::cout << NewCallable (10) << '\n';
bind的第一个参数是函数名,普通函数做实参时,会隐式转换成函数指针。因此 std::bind(callableFunc,_1,2) 等价于std::bind (&callableFunc,_1,2);
_1 表示占位符,位于 <functional> 中,std::placeholders::_1;
第一个参数被占位符占用,表示这个参数以调用时传入的参数为准,在这里调用 NewCallable 时,给它传入了 10,其实就想到于调用 callableFunc(10,2);
2)std::bind 绑定一个成员函数
class Base
{
void display_sum(int a1, int a2)
{
std::cout << a1 + a2 << '\n';
}
int m_data = 30;
};
int main()
{
Base base;
auto newiFunc = std::bind(&Base::display_sum, &base, 100, std::placeholders::_1);
f(20); // should out put 120.
}
bind 绑定类成员函数时,第一个参数表示对象的成员函数的指针,第二个参数表示对象的地址。
必须显示的指定 &Base::diplay_sum,因为编译器不会将对象的成员函数隐式转换成函数指针,所以必须在Base::display_sum 前添加 &;
使用对象成员函数的指针时,必须要知道该指针属于哪个对象,因此第二个参数为对象的地址 &base;
3) 绑定一个引用参数
默认情况下,bind 的那些不是占位符的参数被拷贝到 bind 返回的可调用对象中。但是,与 lambda 类似,有时对有些绑定的参数希望以引用的方式传递,或是要绑定参数的类型无法拷贝。
#include <iostream>
#include <functional>
#include <vector>
#include <algorithm>
#include <sstream>
using namespace std::placeholders;
using namespace std;
ostream & printInfo(ostream &os, const string& s, char c) {
os << s << c;
return os;
}
int main() {
vector<string> words{"welcome", "to", "C++11"};
ostringstream os;
char c = ' ';
for_each(words.begin(), words.end(),
[&os, c](const string & s){os << s << c;} );
cout << os.str() << endl;
ostringstream os1;
// ostream不能拷贝,若希望传递给bind一个对象
// 而不拷贝它,就必须使用标准库提供的ref函数
for_each(words.begin(), words.end(),
bind(printInfo, ref(os1), _1, c));
cout << os1.str() << endl;
}
根据以上的知识,在引入 std::function 接受 bind 对象,可以写出如下的程序:
using write_block_handler = std::function<ssize_t(int, const void*, size_t)>;
bool WriteBlockToBuffer(int, const std::string&, write_block_handler);
bool WritePipe(int fd, const std::string& block)
{
return WriteBlockToBuffer(fd, block, write);
}
bool SendBlock(int sock, const std::string& block)
{
using namespace std::placeholders;
return WriteBlockToBuffer(sock, block, std::bind(send, _1, _2, _3, 0));
}
bool WriteBlockToBuffer(int fd, const std::string& block, write_block_handler handler)
{
if( block.empty() )
{
LOGMESSAGE(WARNING, LOG_MODE, "buffer is empty!");
return false;
}
const char* buf = block.c_str();
size_t total = block.size();
size_t sent = 0;
ssize_t cnt;
// cnt = send(sock, buf + sent, total - sent, 0);
while( (sent < total) && ( (cnt = handler(fd, buf + sent, std::min(4096UL, total - sent))) > 0 ) )
sent += cnt;
if( cnt < 0 || sent < total )
{
LOG(ERROR, LOG_MODE, errno);
return false;
}
return true;
}
九 展示运行进程的工作目录
C/C++ 使用 getcwd 函数:
在 C/C++ 中,您可以使用 getcwd 函数来获取当前工作目录的路径。下面是一个示例:
#include <iostream>
#include <unistd.h>
int main() {
char cwd[1024];
if (getcwd(cwd, sizeof(cwd)) != NULL) {
std::cout << "Current working directory: " << cwd << std::endl;
} else {
perror("getcwd");
return 1;
}
return 0;
}
这个示例使用 getcwd 函数获取当前工作目录,并将其打印到标准输出。
十 Cgi 原理和实现
1. 原理
历史来由
早期的 Web 服务器,只能响应浏览器发来的 HTTP 静态资源的请求,并将存储在服务器中的静态资源返回给浏览器。随着 Web 技术的发展,逐渐出现了动态技术,但是 Web 服务器并不能够直接运行动态脚本,为了解决 Web 服务器与外部应用程序(CGI 程序)之间数据互通,于是出现了 CGI(Common Gateway Interface)通用网关接口。简单理解,可以认为 CGI 是 Web 服务器和运行其上的应用程序进行 “交流” 的一种约定。
简单地说 CGI 就是 web 服务器上的一种执行动态页面计算的外部逻辑计算扩展程序(webserver 和 cgi 程序进行数据交互基于 TCP 协议)。
基本原理:
CGI 的基本思路其实就是把标准输入( STDINT )、标准输出( STDOUT )、标准错误( STDERR )重定向到 web server 和 cgi 外部程序的 tcp 连接,进而直接从标准输入和进程环境变量中读取 web server 输入的数据,向 stdout 和 stderror 中写入参数,以此进行标准的数据交互。
CGI 是 Web 服务器和一个独立的进程之间的协议,它会把 HTTP 请求 Request 的 Header 头设置成进程的环境变量,HTTP 请求的 Body 正文设置成进程的标准输入,进程的标准输出设置为 HTTP 响应 Response,包含 Header 头和 Body 正文。
+--------+ HTTP +--------+ ENV +---------+
| | Request | | STDIN | |
| | +------------> | | +------------> | |
| | | | | CGI |
| Client | | Server | | Program |
| | | | | |
| | <------------+ | | <------------+ | |
| | HTTP | | STDOUT | |
+--------+ Response +--------+ +---------+
cgi 优势
必要性:早期的 Web 服务器,只能响应浏览器发来的 HTTP 静态资源的请求,并将存储在服务器中的静态资源返回给浏览器,无法实现动态计算页面,CGI 通过外部扩展程序的方式,解决了 http 动态页面的问题
稳定性:cgi 是以独立的进程池运行来 cgi,单独一个进程死掉,系统可以很轻易的丢弃,然后重新分配新的进程来运行逻辑
安全性:cgi 和宿主的 server 完全独立, cgi 怎么 down 也不会把 server 搞垮
性能:cgi 把动态逻辑的处理从 server 中分离出来, 大负荷的 IO 处理还是留给宿主 server, 这样宿主 server 可以一心一意作 IO,对于一个普通的动态网页来说, 逻辑处理可能只有一小部分, 大量的图片等静态 IO 处理完全不需要逻辑程序的参与
扩展性:cgi 是一个中立的技术标准, 完全可以支持任何语言写的处理程序(php,java,python…)
语言无关性:CGI 独立于任何语言的,CGI 程序可以用任何脚本语言或者是完全独立编程语言实现,只要这个语言可以在这个系统上运行。
2. 实现

核心函数:bool CgiHandler(const std::string& uri_path, const std::string& argument)
获取到请求的方法,是
GET还是POSTconst std::string& method = _req._request_line._method;创建两个管道,用来沟通
httpserver进程 和cgi进程int pipe_input[2], pipe_output[2]; int ret1 = pipe(pipe_input); int ret2 = pipe(pipe_output);注意,管道数组的命名视角是 httpserver
创建子进程,子进程工作:
关掉 httpserver 的读,写端
close(pipe_input[0]); close(pipe_output[1]); int read_fd = pipe_output[0]; int write_fd = pipe_input[1];将请求方式设置到环境变量
METHOD中。如果请求方式为GET,还需要设置请求参数到环境变量ARGUMENT中if( setenv("METHOD", method.c_str(), 1) == -1 ) {...} if( method == "GET" ) if( setenv("ARGUMENT", (char*)argument.c_str(), 1) == -1 ) {...}将进程的标准输入和标准输出重定向到
cgi程序的管道的读,写端dup2(read_fd , 0); dup2(write_fd, 1);进程替换
execl(uri_path.c_str(), uri_path.c_str(), nullptr);
父进程工作:
关掉
cgi程序管道的的读,写端close(pipe_input[1]); close(pipe_output[0]); int read_fd = pipe_input[0]; int write_fd = pipe_output[1];如果请求方法是
POST,向管道中写入参数后,关闭管道的写端,这样cgi程序在读完参数后,就会读到 0if( method == "POST" ) { if( !HttpUtil::WritePipe(write_fd, argument) ) return false; close(write_fd); }对子进程(
cgi进程)进行等待,并检查状态码。根据状态码,设置响应的状态码。如果子进程异常终止,则将状态码设置为 500,服务器内部错误
如果子进程退出码非 0,则将状态码设置为 400,客户端请求错误
如果子进程退出码为 0,则将状态码设置为 200,OK
最后关闭 httpserver 管道的读端,结束本次响应的读取
int child_status = 0; pid_t ret = waitpid(pid, &child_status, 0); // 检查子进程是否正常退出 if( WIFEXITED(child_status)) { // 检查子进程退出码是否为 0 if( WEXITSTATUS(child_status) == 0 ) { std::string out; // 由于不知道 cgi 程序处理结果的具体大小,所以逐字节读取 // 由于子进程退出,所以已经关闭了管道,最终会读取到 0 while( HttpUtil::ReadPipe(read_fd, &out, 1) ) _resp._response_body += out; _resp._status_code = OK; } else _resp._status_code = Bad_Request; } else _resp._status_code = Internal_Server_Error; close(read_fd); }最后设置响应报文
SetHttpResponse(_resp._status_code); return _resp._status_code == OK;;
十一 浮点数除 0 与 浮点数比较
在 C++ 中,如果一个变量被除以 0,会导致运行时错误。这种情况称为 “除以零” 错误,通常会引发异常或导致程序崩溃。
整数除以零:当整数变量除以零时,通常会引发异常。这个异常的类型和行为取决于编译器和操作系统。在大多数情况下,它会导致程序中断,并可能输出错误消息。
int x = 10; int y = 0; int result = x / y; // 除以零错误浮点数除以零:当浮点数变量除以零时,结果通常是特殊值,例如正无穷大(+∞)或负无穷大(-∞)。这些特殊值表示一个非常大的数或一个非常小的数,取决于除数的符号。没有异常,但结果可能不是您期望的。
double a = 5.0; double b = 0.0; double result = a / b; // 此时 result 可能为 +∞ 或 -∞
SIGFPE 是一个表示浮点异常(Floating-Point Exception)的信号,在 C/C++ 程序中经常用于捕获浮点数运算中的异常情况。当发生浮点异常时,操作系统会向程序发送 SIGFPE 信号,可以通过注册信号处理程序来捕获和处理这个信号。
SIGFPE 通常与以下类型的浮点异常相关联:
- 除以零:当试图将一个数除以零时,会触发除以零异常。例如,
1.0 / 0.0将导致除以零异常。 - 浮点溢出:当浮点数的结果过大而无法表示时,会触发浮点溢出异常。例如,对于某些操作,如
HUGE_VAL * 2.0,可能导致浮点溢出异常。 - 浮点下溢:当浮点数的结果太接近零而无法表示时,会触发浮点下溢异常。例如,对于某些操作,如
0.1 / 1e100,可能导致浮点下溢异常。 - 无效操作:当进行无效的浮点运算时,会触发无效操作异常。例如,对负数取平方根,或者对负数进行对数运算可能导致无效操作异常。
3、浮点数比较
用 "==" 来比较两个 double 的类型应该相等,返回真值完全是不确定的。计算机对浮点数的进行计算的原理是只保证必要精度内正确即可。
我们在判断浮点数相等时,推荐用范围来确定,若 x 在某一范围内,我们就认为相等,至于范围怎么定义,要看实际情况而已了,float,和 double 各有不同 所以:
const float EPSINON = 0.00001;
if((x >= - EPSINON) && (x <= EPSINON)
这样判断是可取的
至于为什么取 0.00001,可以自己按实际情况定义。
比如要判断浮点数 float A 和 B 是否相等,我们先令 float x = A – B ;
并设 constfloat EPSINON = 0.00001; 则
if ((x >= - EPSINON) && (x <= EPSINON)
cout << "A 与B相等" << endl;
else
cout<< "不相等" << endl;
根据上面分析建议在系统开发过程中设计到字符转换建议采用 double 类型,精度设置为 %.8lf 即可,在比较浮点数十建议EPSINON= 0.00000001
深入理解C++浮点数(float、double)类型数据比较、相等判断
根据上面的知识,我们将 caculator_cgi.cc 程序中对结果进行计算的部分改为:
double result;
switch( op_host )
{
case '+':
result = a + b;
break;
case '-':
result = a - b;
break;
case '*':
result = a * b;
break;
case '/':
if( fabs(b - 0) < EPISLON )
raise(SIGFPE);
result = a / b;
break;
case '%':
if( fabs(b - 0) < EPISLON )
raise(SIGFPE);
result = (long long)a % (long long)b;
break;
default:
exit(5);
}
十二 统计项目源代码总长度
#! /bin/bash
find . -type f \( -name "*.cc" -o -name "*.hpp" \) -exec wc -l {} \; | tee .project_code_sum.txt
printf "\ntotal: "
awk '{ sum += $1 } END {print sum}' .project_code_sum.txt
十三 一个 HTTP 请求处理的全过程

十四 谈谈遇到的 BUG
1. unordered_map 没有 const 版本的 operator[] 方法
#include <string>
#include <unordered_map>
#define CONTENT_LENGTH "Content-Length"
class HttpRequest
{
public:
std::string _request_line;
std::unordered_map<std::string, std::string> _request_header;
std::string _request_body;
size_t GetBodySize() const
{
std::string& length = _request_header[std::string(CONTENT_LENGTH)]; // 报错
return std::stoi(length);
}
};
解决方法1: 将 GetBodySize() 设置为 非 const
std::unordered_map<Key,T,Hash,KeyEqual,Allocator>::operator[]
T& operator[]( const Key& key );(1) (since C++11)
T& operator[]( Key&& key );(2) (since C++11)
解决方法2:将使用 find 替换 operator[]
std::unordered_map<Key,T,Hash,KeyEqual,Allocator>::find
iterator find( const Key& key );(1)
const_iterator find( const Key& key ) const;(2)
size_t GetBodySize() const
{
auto it = _request_header.find(std::string(CONTENT_LENGTH));
return std::stoi(it->second);
}
2. recv 错误:Socket operation on non-socket
HttpTask 的简化结构如下:
class HttpTask
{
public:
HttpTask() = default;
HttpTask(int sock) : _sock(sock) {}
void operator()(int tid) {}
~HttpTask()
{
close(_sock);
close(_uri_fd);
}
private:
int _sock;
HttpRequest _req;
HttpResponse _resp;
int _uri_fd;
};
下面请看一个任务从创建,被加入任务队列到被线程池中的线程处理的过程:
HttpTask task(sock); // 析构一次
thread_pool->PushTask(task);
void PushTask(const Task& task)
{
_que.push(task);
}
Task task; // 析构一次
thread_pool->PopTask(&task);
bool PopTask(Task* task)
{
*task = _que.front();
_que.pop(); // 析构一次
}
task(id);
问题就在于由于 task 以对象的方式存储,这个过程中存在拷贝,声明周期终结,会调用析构函数,导致 recv 之前,sock 已经被 close !
3. putenv
setenv 和 putenv 都是用于操作环境变量的函数,但它们在用法和行为上有一些重要的区别:
- 用法:
setenv:setenv是一个标准库函数,通常在<cstdlib>(或<stdlib.h>)头文件中定义。它接受三个参数:变量名、变量值和一个标志,用于指定是否覆盖已存在的环境变量。putenv:putenv也是标准库函数,通常在<cstdlib>(或<stdlib.h>)中定义。它接受一个单个参数,即以"name=value"格式的字符串,用于设置环境变量。
- 覆盖行为:
setenv允许您明确指定是否要覆盖已存在的环境变量。通过将第三个参数设置为非零值,您可以强制覆盖现有变量,而将其设置为零则不会覆盖。putenv不提供明确的覆盖标志。它通常会覆盖已存在的环境变量,如果不存在则创建一个新的环境变量。
- 内存管理:
setenv会自动管理内存分配和释放,因此它会复制传递给它的变量值,而不需要您手动分配或释放内存。putenv不会自动复制变量值,而是直接使用传递给它的字符串。这意味着如果您在调用putenv后更改了传递的字符串,环境变量的值也会相应更改。这可能导致一些潜在的问题,因此需要格外小心。‘
在 CgiHandler 中通过 putenv 加入新的环境变量时,如果像下面这样将 arg_env 定义在 if 之内,那么 Ggi 程序会获取不到环境变量 ARGUMENT 的值。
int pid = fork();
if( pid == 0 )
{
if( method == "GET" )
{
std::string arg_env = "ARGUMENT=" + argument;
putenv((char*)arg_env.c_str());
}
}
但是如果将 arg_env 定义在 if 外,则 Cgi 程序可以获取到 arg_env 的值,比如:
int pid = fork();
if( pid == 0 )
{
std::string arg_env;
if( method == "GET" )
{
arg_env = "ARGUMENT=" + argument;
putenv((char*)arg_env.c_str());
}
}
原因分析:
首先就是因为
putenv直接将 指针 加入环境中(glibc2.0 是使用拷贝,glibc2.1.2 是直接使用指针),所以这种做法是不安全的。 相比之下setenv更加安全,但是setenv可能会造成内存泄露?所以,由于
putenv直接使用 string 内部的 char* 指针,该指针是一个位于堆上的指针,当arg_env被析构时,再对该指针的访问变为非法!并且由于 exec* 对程序的替换,堆也被一同替换,在新的地址空间中,该指针指向的内存可能并未被分配!
那么为何将
arg_env写在if外Cgi程序就可以看到了?可能的解释就是,在进行 exec* 替换的时候,会对环境变量进行深拷贝,这样合法的环境变量自然会被拷贝!
#include <iostream>
#include <cstdlib>
#include <string>
int main()
{
char* str_c;
{
std::string str("METHOD=GET");
str_c = (char*)str.c_str();
//putenv(str_c);
setenv("METHOD", str_c, 1);
}
// 如果是调用 putenv,那么下面就无法获取到 METHOD
// 而 setenv 则可以获取到!
*str_c = 0;
const char* env = getenv("METHOD");
if( env == nullptr )
std::cout << "METHOD is empty!" << std::endl;
else
{
std::cout << env << std::endl;
}
}
https://blog.csdn.net/u012707739/article/details/80170671)
4. current work directory
程序的 cwd(当前工作目录),为启动该程序时所在的目录。
比如如下文件结构:
.
├── httpserver
└── wwwroot
├── calculator_cgi
└── .result.html
我们在当前目录运行 httpserver 程序,httpserver 程序调用 exec* 程序打开了 wwwroot/calculator_cgi 程序,新程序需要打开,.result.html ,open 函数不能这样写:
open(".result.html", O_RDONLY)
而应该写成如下的格式:
#define WEBROOT "wwwroot/"
#define RESULT_PAGE ".result.html"
std::string result_path = WEBROOT;
result_path += ".result.html";
// httpserver 调用
int render_fd = open(result_path.c_str(), O_RDONLY);
5. 管道容量限制
...
</ul>
<p> </p>
<h2 id='评价'><span>评价</span></h2>
<ul>
<li>
<p><span>注重代码可读性/耦合度</span></p>
</li>
show_resume.cc 中是这样打印日志的:
char buffer[1024];
ssize_t cnt;
while( ( cnt = read(resume, buffer, sizeof(buffer) - 1) ) > 0 )
{
buffer[cnt] = 0;
std::cerr << buffer;
std::cout << buffer;
}
管道其实是一个在内核内存中维护的缓冲器,这个缓冲器的存储能力是有限的。一旦管
道被填满之后,后续向该管道的写入操作就会被阻塞直到读者从管道中移除了一些数据为止。从 Linux 2.6.11 起,管
道的存储能力是 65,536 字节。
从理论上来讲,没有任何理由可以支持存储能力较小的管道无法正常工作这个结论,哪怕管道的存储能力只有一个字节。使用较大的缓冲器的原因是效率:每当写者充满管道时,内核必须要执行一个上下文切换以允许读者被调度来消耗管道中的一些数据。使用较大的缓冲器意味着需执行的上下文切换次数更少。
Linux 特有的 fcntl(fd, F_SETPIPE_SZ, size) 调用会将 fd 引用的管道的存储能力修改为至少 size 字节。非特权进程可以将管道的存储能力修改为范围在系统的页面大小到 /proc/sys/fs/pipe-max-size 中规定的值之内的任何一个值。pipe-max-size 的默认值是 1048576 字节。
通过 ls 命令发现,要传输的 wxc_resume.html 的大小刚好超过了 pipe 的默认大小
$ ls -l wxc_resume.html
-rw-rw-r-- 1 ubuntu ubuntu 67286 Sep 17 09:34 wxc_resume.html
$ cat /proc/sys/fs/pipe-max-size
1048576
解决办法:
- 增大
pipe大小 - 让
httpserver提前开始读取